"Dann schauen wir dem Ding mal unter die Haube..."
Natürlich ist es spannend, sich einmal genauer anzuschauen, was bei der Ausführung eines Codes eigentlich passiert. Die Java-Engine funktioniert wie folgt:
Write once Run anywhere
Java ist WORA (Write once Run anywhere). Das bedeutet, der Java-Quellcode ist auf allen Betriebssystemen lauffähig. Der vom Javac-Compiler generierte Bytecode (.class) kann auf jedem Betriebssystem ausgeführt werden.
Jetzt gehts los...
Sprechen wir erst mal davon, was der Prozessor des Computers für Fähigkeiten beherrscht. Der Prozessor kennt nämlich nur ganz grundlegende Operationen wie zum Beispiel die Grundrechenarten und das Lesen sowie Schreiben im Arbeitsspeicher.
Alle Programme
die man auf dem Computer ausführt bestehen ausschließlich aus tausenden von solchen
grundlegenden Operationen. Diese werden in Maschinencode gespeichert, wobei ein solcher Maschinencode einfach die Hintereinanderreihung von Nummern ist und jede Nummer für eine Operation steht.
Die Befehle einer Programmiersprache sind
so gebaut, dass man durch ihre Kombination aufgabenorientiert dem Computer Anweisungen geben kann und nicht mehr gezwungen ist alles in Grundrechenarten
oder Speicherzugriffe herunter zu brechen. Zu einer Datei, die Anweisungen in einer Hochsprache enthält, sagt man Quelltext (Source Code). Allerdings ist ein solcher Quelltext nicht mehr direkt
vom Prozessor ausführbar, denn ein Befehl aus der Hochsprache steht häufig für eine Aneinanderreihung von vielen Maschinenbefehlen, oft in Abhängigkeit zu vorhergehenden
Befehlen der Hochsprache. Aus diesem Grunde muss man ein Übersetzungsprogramm –
der sogenannte Compiler – verwenden, um aus dem in einer Hochsprache geschriebenen
Quelltext wieder Maschinencode zu erzeugen.
Einige der Vorteile von Java als Programmiersprache sind folgende:
- Objektorientierte Sprache - Programme werden in Modulen erstellt, was bedeutet, dass wir diese Programme wiederverwenden können.
- Plattformunabhängigkeit - Das Programm kann mit Hilfe von der JVM (Java Virtual Machine) auf jeder anderen Maschine ausgeführt werden.
- Sicher - Java hat einen Sicherheitsmanager, der den Zugriff auf Klassen definiert.
- Multithreading - kann mehrere Aufgaben gleichzeitig ausführen.
- Speicher - Java verwendet Heap und Stack für die Speicherzuweisung, was uns hilft, Daten einfach zu speichern und abzurufen.
JDK, JVM, JRE?
Im Überblick

Java-Development-Kit (JDK) : Das Java-Entwicklungskit:
Ein JDK ist eine Softwareentwicklungsumgebung, die zum Erstellen von Applets und Java-Anwendungen verwendet wird.
Java Runtime Environment-Software(JRE + Compiler + Debugger JRE):
Die Java Runtime Environment-Software wurde entwickelt, um andere Software auszuführen. So benötigen wir die JRE auch um Java auszuführen. Die JRE enthält Klassenbibliotheken, Ladeklassen und andere Komponenten zum Ausführen von Applets / Java-Anwendungen. Dazu gehört auch die JVM.
Java Virtual Machine (JVM):
Die virtuelle Maschine ist ein Teil der Java-Laufzeitumgebung(JRE), auf der der Java-Bytecode ausgeführt wird. Sie macht Java portabel. Die JVM kommt mit einem JIT (Just-In-Time)-Compiler, der Java-Quellcode in Low-Level-Maschinensprache konvertiert. Der Bytecode ist verständlich, sofern eine JVM auf einem Betriebssystem installiert ist.
Die Java-JIT-Kompilierung
"Die Just-In-Time (JIT)-Kompilierung ist auch als dynamische Kompilierung bekannt."
Was läuft also "under the hood" bei der Kompilierung?
Das Programm wird während der Laufzeit in nativen Code kompiliert, um die Leistung zu verbessern. Bei der JIT-Kompilierung wird bytecode(.class) übersetzt in Maschinencodeanweisungen von laufenden Maschinen.
Der resultierende Maschinencode ist für die "Central Processing Unit(CPU/Hauptprozessor)-Architektur" der laufenden Maschine optimiert.
Die Kompilierung erfolgt zur Laufzeit des Programms (im Gegensatz zur Ausführung).
Da die Kompilierung zur Laufzeit erfolgt, hat der JIT-Compiler Zugriff auf dynamische Laufzeitinformationen, wodurch er bessere Optimierungen vornehmen kann. Dabei soll die Effizienz der Ausführung von Maschinencode, die Ineffizienz der Neukompilierung von Programmen bei jeder Ausführung überwinden.
Optimierungen
Die JVM führt den Bytecode aus und zählt, wie oft die Funktion ausgeführt wird. Wenn die Anzahl das vordefinierte Limit überschreitet, wird via JIT Code in Maschinensprache kompiliert, der direkt vom Prozessor ausgeführt werden kann. Beim nächsten Mal wird die Funktion berechnet, der kompilierte Code wird im Gegensatz zur normalen Interpretation erneut ausgeführt. Das führt zu einer schnelleren Ausführung.
Der Heap- und Stack-Speicher
Um eine Anwendung optimal auszuführen, teilt die JVM den Speicher in Stack & Heap-Speicher auf. Stack und Heap sind Teile des Arbeitsspeichers und beide sehr unterschiedlich strukturiert. Du kannst dir den Heap tatsächlich als Haufen vorstellen, auf dem jede Menge Platz ist. Während der Stack von der Größe her stark begrenzt ist, kann der Heap anwachsen bis die Speichergrenze auf Prozessebene erreicht ist.
Dafür ist der Heap aber intern nicht so einfach zu verwalten, was ihn langsamer als den strukturierten und effizienten Stack macht. Auf dem Heap angelegter Speicher muss auch explizit wieder freigegeben werden (z.B. durch den Garbage Collector).
Um auf den Heap zuzugreifen, werden Referenzen verwendet also sozusagen Zeiger auf dem Stack, die auf Objekte verweisen, die auf dem Heap liegen. Neue Objekte werden immer im Heap-Space erstellt und die Referenzen auf diese Objekte werden im Stack-Speicher abgelegt.
Die Referenzen/Zeiger auf dem Stack, beinhalten anders beschrieben die Speicheradresse des Objektes.
Da auf dem Heap angelegte Objekte nicht auf den lokalen Sichtbarkeitsbereich beschränkt sind, kann global darauf zugegriffen werden (sofern ein Zeiger oder eine Referenz vorhanden ist).
Heap
- Führt tatsächliche Objekte
- Hat eine dynamische Speicherzuweisung für Java-Objekte und JRE-Klassen zur Laufzeit
- Ist wie ein String-Pool
- Ist nicht Thread-sicher: muss durch ordnungsgemäß synchronisierenden Code geschützt werden
- Wird beim Start von JVM erstellt und kann während der Ausführung der Anwendung größer/kleiner werden.
- Wenn der Heap voll ist, wird der Garbage Collector eingesetzt. So werden nicht mehr benötigte Gegenstände geräumt und so Platz für neue Objekte geschaffen.
- Objekte können von überall in der Anwendung aufgerufen werden
Young Generation: Alle neuen Objekte werden hierhin zugewiesen.
Old / Tenured Generation: Für Objekte, die in der Young Gen gespeichert wurden, und einen gewissen Schwellenwert(vorab festgelegt) des Lagerns/Alterns überschritten haben. Sobald die Schwelle erreicht ist, werden diese Objekt in die Old Gen verschoben.
Permanent Generation: JVM-Metadaten für Laufzeitklassen und Anwendungsmethoden.
Stack
- Der Stack wird für die Ausführung eines Threads verwendet
- Führt primitive Werte, die für eine Methode spezifisch sind
- Verweise aus Methoden auf Objekte, die sich im Heap befinden
- thread-safe : jeder Thread wird in einem eigenen Stack betrieben
- in LIFO-Reihenfolge ("last in - first out") referenziert
- Wenn eine neue Methode aufgerufen wird, wird ein neuer Block oben auf dem Stapel erstellt, der für diese Methode spezifische Werte enthält (z. B. primitive Variablen und Verweise auf Objekte).
- Methode beendet die Ausführung -> entsprechender Stack wird geleert, Prozess geht zurück zum Aufruf der Methode. Nun ist wieder Speicherplatz für die nächste Methode verfügbar
Heap & Stack
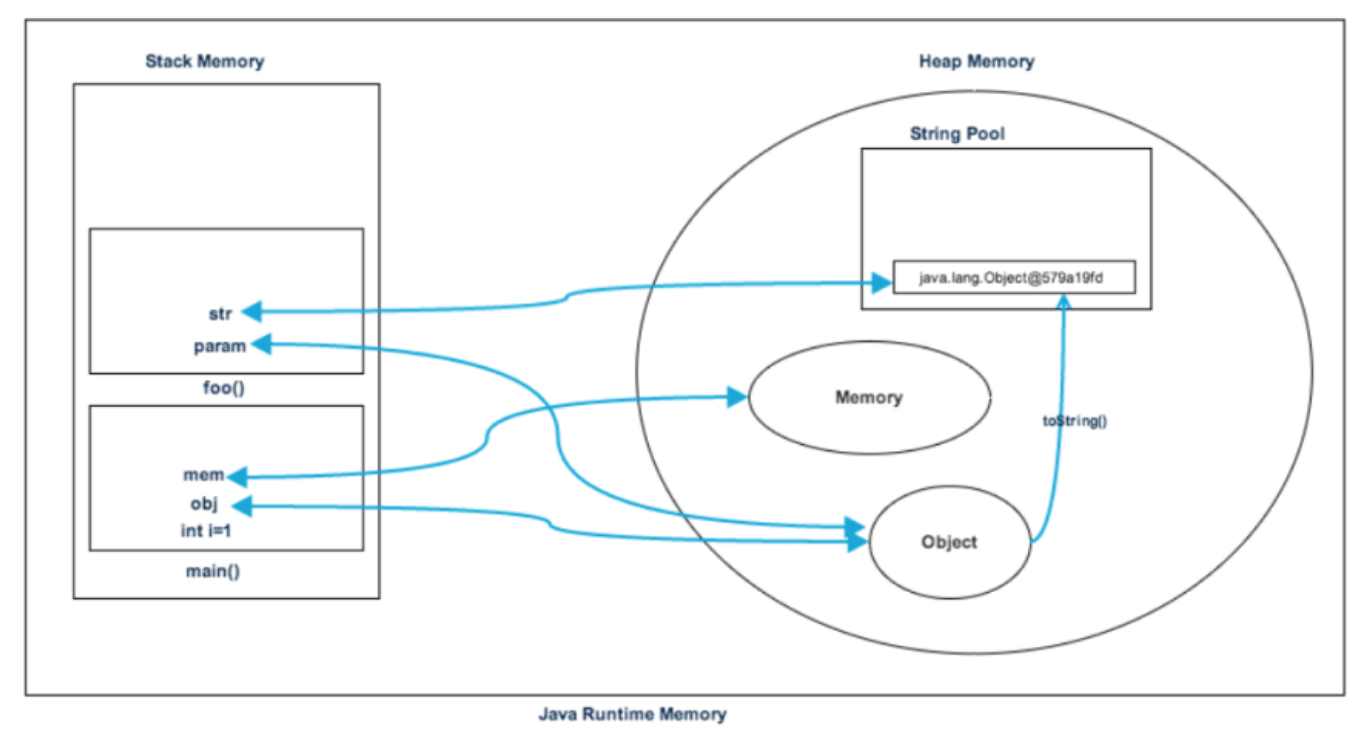
- Zusammenfassung
- Programm wird ausgeführt und Laufzeitklassen in Heaps-Space geladen
- main()-Methode wird in Zeile 1 gefunden, erstellt zur Laufzeit den Stack-Speicher, der vom Thread der main()-Methode verwendet werden soll.
- Immer wenn ein neues Objekt erstellt wird, kommt der Heap-Speicher zum Einsatz
- Der Stack-Speicher enthält die Referenz für das neue Objekt.
- Wenn eine neue Methode aufgerufen wird, wird ein neuer Block auf dem Stack erstellt (LIFO).
- Eine String-Referenz im Stack-Speicher, die auf den String-Pool im Heap-Space verweist.
- Wenn die Methode (foo()) beendet wird, wird der Stack wieder frei (der für die Funktion erstellte Stack-Speicher wird zerstört)
- Geht den nächsten Schritt im nächsten Programm (von oben nach unten in der main())